
Photo: Lukas Blazek via Unsplash
Depuis le mois de mars 2020, les journaux télévisés, mais aussi les unes de nos quotidiens mettent en scène, presque quotidiennement, les chiffres de la pandémie. Les taux d’incidence, nombres de décès, pourcentage de vaccination et R0 sont des éléments centraux de la trame narrative du Covid-19.
Les chiffres posent le décor et permettent de mesurer le succès des mesures prises par les gouvernements. Parfois, ils deviennent les personnages de l’intrigue lorsque la réouverture de certains secteurs d’activités ou la levée de certaines mesures dépendent de leur évolution. D’une certaine manière ils sont le visage que les médias d’information donnent au virus, ils le réifient, et n’auront sans doute que très rarement été autant utilisés pour construire la représentation médiatique d’un événement.
En termes de narration journalistique, cette mise en scène des chiffres n’est pas neuve. Elle prend sens dans le contexte du développement du “data-journalism” qui peut être défini comme un nouvel ensemble de pratiques journalistiques (De Maeyer et al 2015, Bradshaw 2014) combinant deux éléments :
- L’utilisation de techniques de traitement de données statistiques pour produire de l’information. Techniques d’abord issues des sciences sociales (avec le projet du New precision journalism défini par Philip Meyer dès 2002) puis, à partir des années 2010, des data science, autour de ce qui peut être appelé avec Flew et al. (2012) le computational journalism.
- L’adoption de techniques et d’outils informatiques de datavisualisation également développés par des data scientistes et utilisés pour créer de nouvelles manières, plus efficaces et plus engageantes, de raconter l’information. Ces nouvelles narrations utilisent la mise en image des chiffres et le développement d’interfaces web interactives pour accroitre l’immersion du récepteur dans les récits informationnels afin d’augmenter l’intelligibilité et la mémorisation des informations présentées (voir par exemple une définition du projet de la datavisualisation : Segel & Heer 2010).
Sans être neuve, la narration par les chiffres en temps de pandémie diffère cependant de l’émergence du data-journalism par son omniprésence et par le fait qu’elle s’est sans doute imposée à des journalistes qui n’avaient pas forcément l’habitude de la pratiquer.
De très bonnes narrations ont été produites. Par exemple la visualisation dynamique de l’utilité des mesures de distanciation pour « aplatir la courbe » des contaminations publiée par le Washington Post qui serait l’article publié en ligne le plus lu de l’histoire de ce journal, ou encore l’article du site belge RTBF info qui raconte de manière dynamique une année de pandémie par ses chiffres .
Mais de nombreuses erreurs en termes de visualisation et utilisation de données sont également commises de manière récurrente.
Dans cet article nous pointons, sur base des principes généralement considérés comme de bonnes pratiques dans le champ de la datavisualisation, quatre erreurs à ne pas commettre lorsque l’on souhaite utiliser la mise en image des chiffres pour raconter la pandémie :
- L’utilisation de données brutes à la place de données normalisées lorsque l’on compare la situation de différents pays
- La distorsion des données résultant d’une mauvaise graduation des axes des graphiques
- L’utilisation de données en dehors de leur contexte interprétatif
- Le manque de minimalisme pouvant mener à la production de « chartjunk »
1. L’utilisation de données brutes à la place de données normalisées lorsque l’on compare la situation de différents pays
Une première erreur courante, rencontrée dans différentes familles de visualisations telles que les cartes choroplèthes, les diagrammes à barres ou les séries temporelles, est l’utilisation de données brutes plutôt que de données normalisées.
Cette erreur consisterait, par exemple, à comparer le nombre brut (non normalisé) de décès attribués au COVID-19 entre la Chine et la Macédoine du Nord. Dans ces deux pays, le nombre de décès attribués officiellement au COVID-19 à la date du 28 avril 2021 était d’environ 4700 (4636 en Chine versus 4772 en Macédoine du Nord).
Il ne serait pourtant pas correct d’affirmer que ces pays sont autant endeuillés l’un que l’autre, tant la différence entre leur population est importante (1,5 milliards d’habitants en Chine versus 2 millions d’habitants en Macédoine du Nord). Rapportés au million d’habitants (Mhab), on observait le 28 avril 2021 764 fois plus de décès en Macédoine du Nord (2291 décès/Mhab) qu’en Chine (3 décès/Mhab).
Aussi simple soit cette démarche de normalisation des données, de nombreuses visualisations utilisées pour comparer l’impact du COVID-19 entre les pays, reposent pourtant sur des valeurs brutes. Au moment d’écrire ces lignes, fin avril 2021, de nombreux articles de presse annoncent ainsi que l’Inde est devenu le deuxième pays le plus touché au monde par le virus après le Brésil en se basant sur le chiffre brut de nouvelles contaminations hebdomadaire dans les deux pays.
L’exemple ci-dessous illustre les erreurs auxquelles l’utilisation de données brutes peut conduire en termes de production d’information. Les tableaux présentent deux classements différents des pays les plus endeuillés par le Covid-19 depuis le début de la pandémie. Le classement 1, (à gauche) repose sur des données non normalisées (chiffres bruts) alors que le classement 2 sur des chiffres normalisés (à droite).
 Tableau 1. Classement des cinq pays européens les plus endeuillés par le coronavirus COVID-19 au 28 avril 2021, selon les valeurs brutes (gauche) et selon les valeurs normalisées (droite). Source : https://www.worldometers.info/coronavirus/
Tableau 1. Classement des cinq pays européens les plus endeuillés par le coronavirus COVID-19 au 28 avril 2021, selon les valeurs brutes (gauche) et selon les valeurs normalisées (droite). Source : https://www.worldometers.info/coronavirus/
2. La distorsion des données résultant d’une mauvaise graduation des axes des graphiques
Une deuxième erreur encore plus courante dans les diagrammes à barres ou les séries temporelles est la distorsion des données.
Cette erreur consiste à tronquer l’axe des abscisses ou des ordonnées pour montrer des effets disproportionnés dans les données, induisant une mauvaise perception de la réalité.
Dans l’exemple ci-dessous, la longueur des barres de la Figure 1 à gauche reflète exactement l’effet dans les données : il y a eu 1,5 fois plus de décès par million d’habitants en République tchèque qu’en Pologne.
La longueur des barres de la Figure 1 à droite déforme par contre l’effet réel dans les données, faisant croire qu’il y aurait eu 4,5 fois plus de décès par million d’habitants en République tchèque qu’en Pologne.
L’effet montré dans le graphique de droite est trois fois plus important qu’il ne l’est en réalité. Ce graphique est donc mensonger, son lie factor est de 3. Alors que les données présentées sont correctes (et que le graphe utilise bien des données normalisées), l’interprétation que le lecteur va en faire sera très certainement erronée car le producteur de la visualisation n’aura pas donné au lecteur les informations nécessaires à leurs bonne compréhension (il manque l’échelle valide de comparaison commune à tous les pays).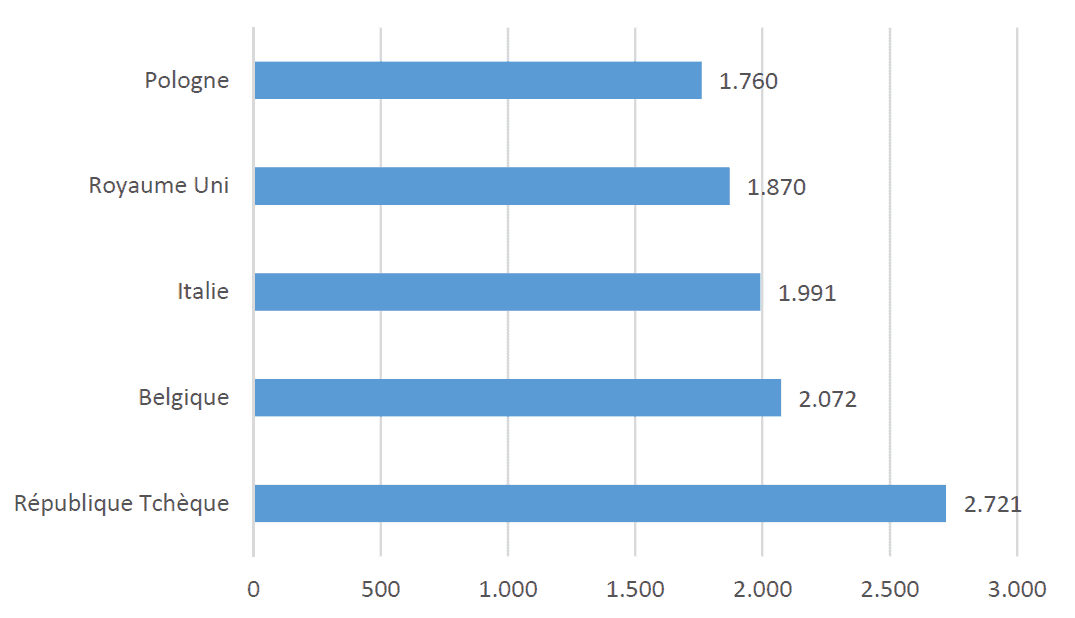
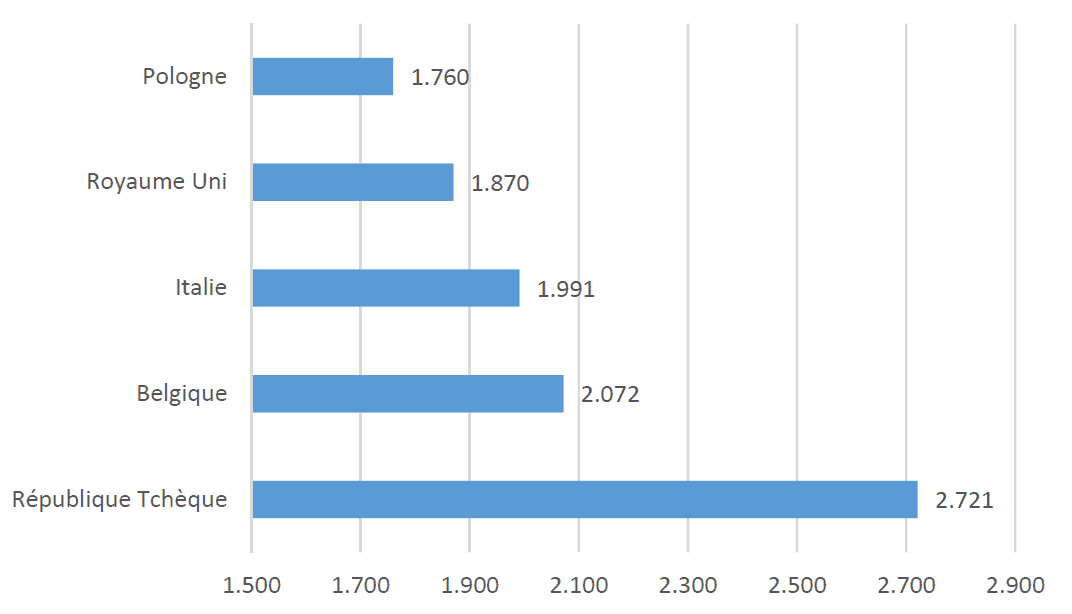 Figure 1. Deux diagrammes à barres montrant le nombre de décès par million d’habitants au 28 avril 2021 dans une sélection de pays européens, sans distorsion des données (en haut) et avec distorsion des données (en bas).
Figure 1. Deux diagrammes à barres montrant le nombre de décès par million d’habitants au 28 avril 2021 dans une sélection de pays européens, sans distorsion des données (en haut) et avec distorsion des données (en bas).
Une autre stratégie pour déformer les données consiste à combiner plusieurs échelles au sein du même graphique. La Figure 2 ci-dessous utilise par exemple sept échelles différentes au total dans une même visualisation : deux échelles horizontales différentes pour le temps (une échelle pour la période 1973-1978 et une échelle pour l’année 1979) et cinq échelles verticales différentes pour le prix du baril (une échelle pour la période 1973-1978 et quatre échelles différentes pour l’année 1979). La hauteur des barres verticales donne l’impression que le prix du baril augmente de plus de 150% en 1979 alors que l’augmentation n’est que de 15%. L’effet dans ce graphique est dix fois plus important qu’il ne l’est en réalité. Figure 2. Variations d’échelle. Source : http://jcsites.juniata.edu/faculty/rhodes/ida/graphicalIntRedes.html
Figure 2. Variations d’échelle. Source : http://jcsites.juniata.edu/faculty/rhodes/ida/graphicalIntRedes.html
3. L’utilisation de données en dehors de leur contexte interprétatif
Une troisième erreur courante dans les séries temporelles ou les représentations statistiques est la présentation des données hors contexte. Cette erreur consiste à montrer un phénomène de manière isolée, privant ainsi l’audience des clés de lecture nécessaires à sa compréhension. Dans les séries temporelles, on observe cette erreur lorsque la période analysée est trop courte ou lorsqu’une seule modalité est présentée.
Poussée à l’extrême, cette erreur est illustrée sur la Figure 3 à gauche où le diagramme ne contient qu’une seule barre, privant ainsi l’audience des points de repère nécessaires à la compréhension des données. Elle est corrigée sur la Figure 3 à droite avec l’ajout d’autres modalités.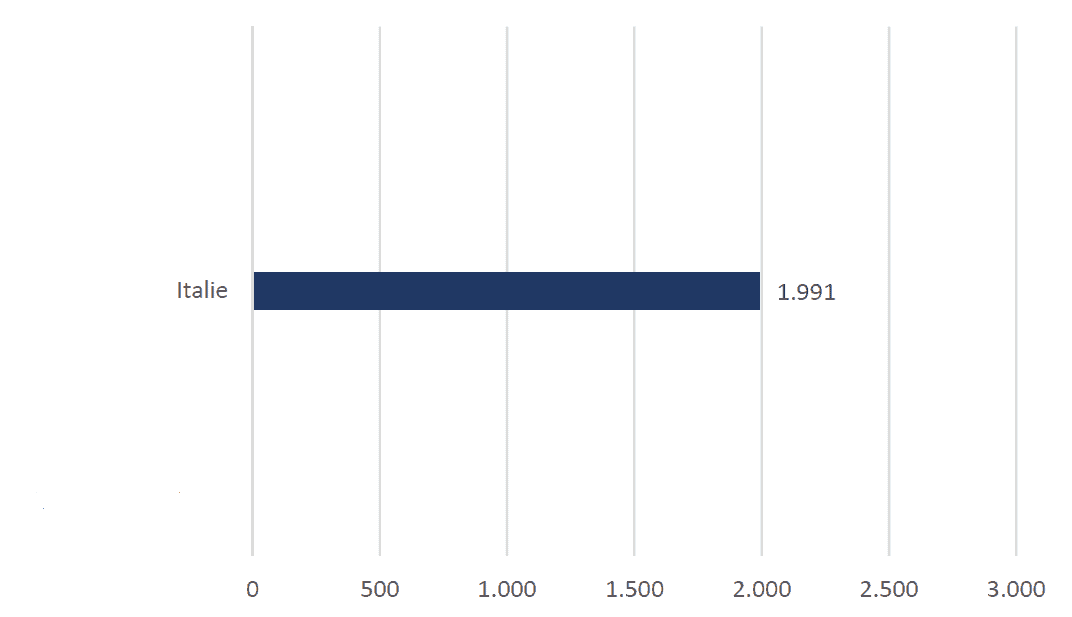
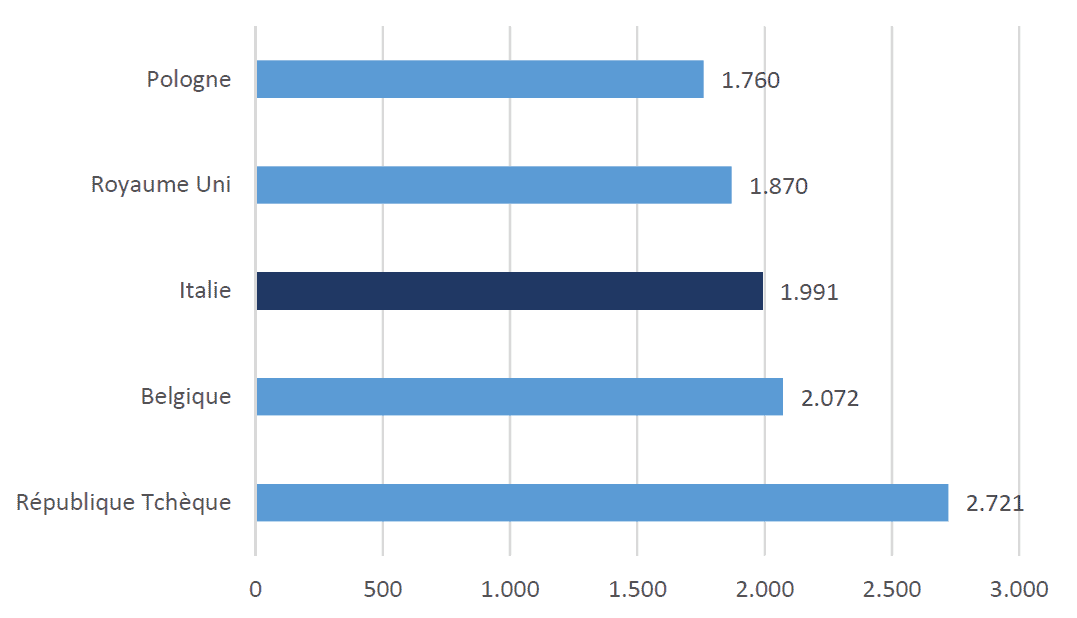
Figure 3. Deux diagrammes à barres montrant le nombre de décès par million d’habitants en Italie au 28 avril 2021, hors contexte (en haut) et dans le contexte (en bas).
Cette erreur peut se comprendre car la plupart des médias d’information produisent pour un marché national. La tentation de ne présenter que les chiffres de l’épidémie pour son pays peut être grande, mais si elle n’est pas réalisée en la mettant en perspective, par exemple, avec les pays voisins, elle peut donner lieu à une mauvaise interprétation de la situation sanitaire du pays. Cela peut par exemple mener le lecteur à attribuer l’évolution des courbes à des mesures prises au niveau national, alors qu’une évolution similaire des courbes observée dans des pays frontaliers, n’ayant pas adopté les mêmes mesures au même moment, permettrait de nuancer cette attribution causale potentiellement erronée.
4. Le manque de minimalisme pouvant mener à la production de « chartunk »
Une autre tendance actuelle est l’utilisation de chartjunk. Edward Tufte, spécialiste reconnu en datavisualisation introduit et définit le chartjunk dans son ouvrage The visual display of quantitative information (2001 [1983]) comme tout élément d’une visualisation inutile à la compréhension des données ou qui détourne l’audience de la substance des données.
Ainsi, le chartjunk inclut les illusions d’optique, les effets moirés, les effets 3D, les grilles, les arrière-plans trop chargés ou encore les décorations (Figure 4). Les exemples extraits de l’ouvrage de Tufte sont disponibles ici, d’autres exemples relatifs au COVID-19 sont disponibles ici.
De manière générale, tout élément visuel, ou interactif (comme le scrolling), qui ne permet pas au lecteur de réaliser le travail cognitif d’interprétation des chiffres doit être évité. Le lecteur pouvant être cognitivement absorbé par l’interaction ou par le caractère esthétique de la représentation et non plus par le travail interprétatif que nécessite la réception d’une narration par les chiffres.


Figure 4. Bons exemples de chartjunk.
Références
Bradshaw Paul, 2014, « Data journalism », In. Lawrie Zion, David Craig, Ethics for digital journalists: Emerging best practices, London, Routledge, p. 202‑219.
De Maeyer Juliette, Libert Manon, Domingo David, Heinderyckx François, et al., 2015, « Waiting for Data Journalism », Digital Journalism, vol. 3, n° 3, p. 432‑446.
Flew Terry, Spurgeon Christina, Daniel Anna et Swift Adam, 2012, « The Promise of Computational Journalism », Journalism Practice, vol. 6, n° 2, p. 157‑171.
Meyer Philip, 2002, Precision Journalism: A Reporter’s Introduction to Social Science Methods, 4ème édition, Lanham, Rowman & Littlefield Publishers.
Segel Edward et Heer Jeffrey, 2010, « Narrative Visualization: Telling Stories with Data », IEEE Transactions on Visualization and Computer Graphics, vol. 16, n° 6, p. 1139‑1148.
Tufte Edward R., 2001 [1983], The Visual Display of Quantitative Information, 2nd édition. Cheshire, Graphics Press USA.
Cet article est publié sous licence Creative Commons (CC BY-ND 4.0). Il peut être republié à condition que l’emplacement original (fr.ejo.ch) et les auteures soient clairement mentionnés, mais le contenu ne peut pas être modifié.

Tags: covid-19, data, datajournalisme, datavisualisation, données



















