
Des étudiants en journalisme ont conçu une série de vidéos pour illustrer la vie en Suisse en 2050. (Source : Instagram de l’AJM)
Imaginer la Suisse en 2050 en illustrant les contenus à l’aide d’outils d’intelligence artificielle (IA) de génération et d’animation d’images, voici le défi lancé à la vingtaine d’étudiants du master en Journalisme de l’Académie du journalisme et des médias (AJM) dans le cadre du cours « Newslab ». Une expérience riche qui a fait émerger chez les étudiants et leurs encadrants des réflexions sur les potentialités et les limites des IA génératives d’images dans une production journalistique.
En collaboration avec le groupe d’information locale ESH Médias, nous avons proposé à la vingtaine d’étudiants de notre cours « Newslab » de concevoir une série de 7 vidéos à diffuser en amont du premier Forum climat Suisse, le 18 juin, sur les comptes Instagram des journaux du groupe (Arcinfo, Le Nouvelliste et La Côte). Les étudiants ont eu un gros mois pour s’organiser puis dérouler les différentes étapes du projet (idéation, recherche d’informations, production, post-production, etc.) jusqu’à la diffusion finale. Assez rapidement, la classe s’est accordée sur un concept facilement déclinable : imaginer sept « témoins du futur » incarnant divers thèmes tels que l’alimentation, l’énergie, la migration climatique, l’eau, les écosystèmes, le transport et la santé.
S’essayer au journalisme prospectif
Les premières difficultés du projet n’ont pas été techniques mais plutôt éditoriales : comment empoigner un tel sujet en s’inscrivant dans une démarche journalistique ? Un journalisme d’impact et concernant, fondé sur des scénarios étayés scientifiquement, sans tomber dans la science-fiction pure, le pessimisme exacerbé ou le militantisme. Pour cette partie du travail, ce n’est pas l’IA qui a été mobilisée, mais plutôt des experts et scientifiques qui ont bien voulu esquisser des pistes réalistes pour les 25 prochaines années, fournissant un socle solide aux récits. Comme le résume un étudiant, « au fil de l’exercice, ce type de journalisme s’est avéré très connecté aux valeurs du métier. La recherche de la vérité n’existe pas seulement dans le présent, elle a également une place dans le futur. » Une approche des sujets originale, qui visait à « repérer des signaux faibles pour penser quelles seront les principales tendances de 2050 et éclairer le monde de demain. Une autre vision de ce que peut être le journalisme. »
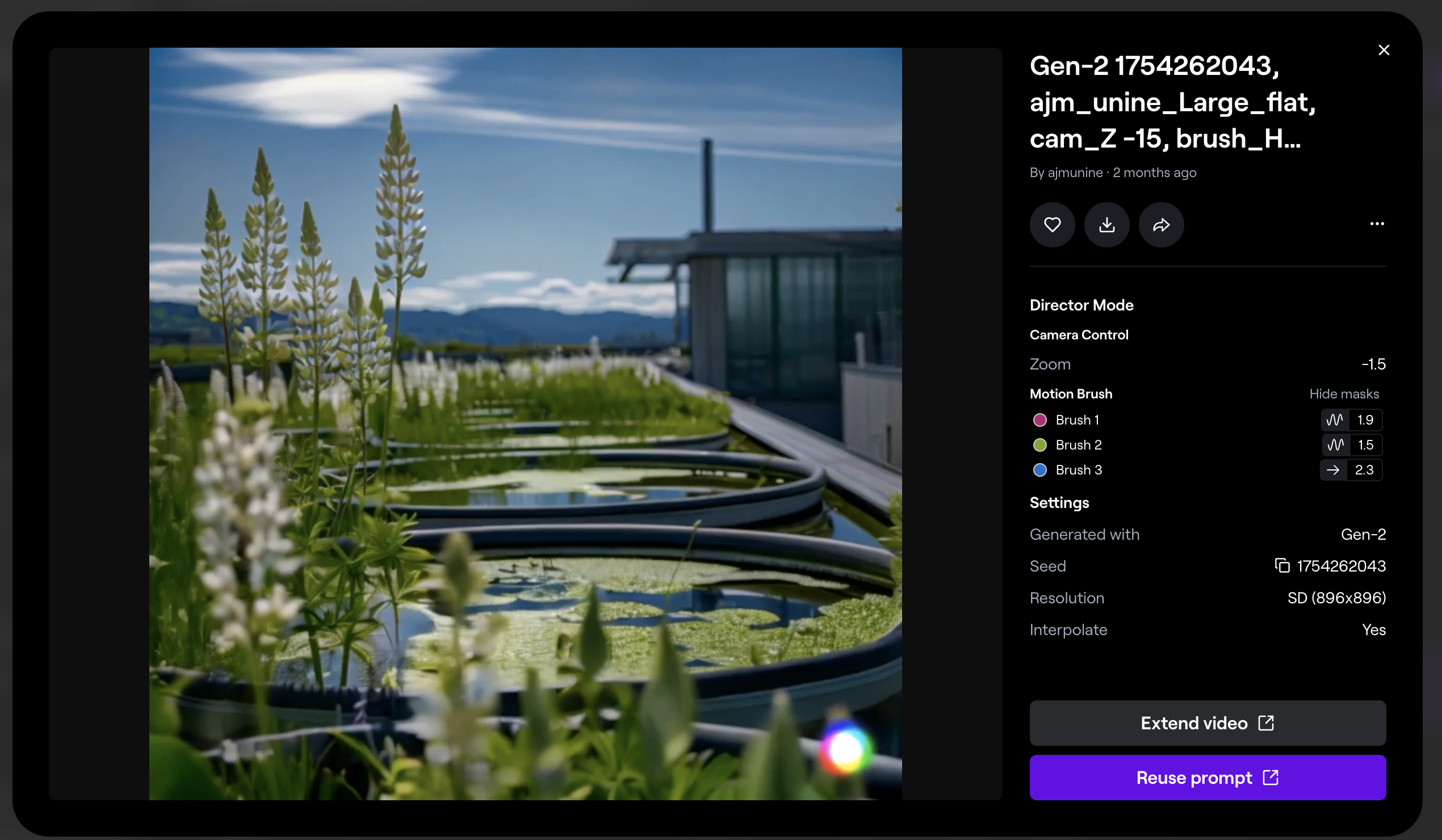
Animation d’une image générée en vidéo avec Runway.
Les sources mobilisées par les étudiants ont toutes été mentionnées dans le descriptif du post accompagnant chacune des vidéos. Une exigence de transparence d’autant plus importante pour un exercice de journalisme fiction. Des traces des recherches sont même présentes dans certaines vidéos sous la forme d’archives datant de… 2024. Une manière d’intégrer des sources et des liens actuels pour offrir des prolongements à chaque sujet, mais également d’asseoir la crédibilité des récits proposés.
L’IA comme plus-value pour illustrer le futur
L’utilisation des outils d’IA était un objectif initial de l’équipe pédagogique : permettre aux étudiants de les maîtriser, d’explorer leurs potentialités et leurs limites, et de développer leur esprit critique. Il était aussi crucial que cela apporte une valeur ajoutée journalistique. L’idée de se projeter dans le futur a naturellement justifié cet usage, dans un contexte où la production de contenus entièrement générés par l’IA dans le journalisme pose de vives (et essentielles) questions. Cette approche intégrale a été soigneusement encadrée lors de la diffusion auprès du public (dans le générique des vidéos et le texte qui les accompagne).
Quels outils pour quels usages ?
Pour réaliser ces vidéos, la classe a testé et mobilisé plusieurs outils. Pour la génération des images, le choix s’est assez rapidement porté sur MidJourney en raison des fonctionnalités proposées, souvent plus avancées que celles d’autres outils.
L’outil Firefly a été davantage utilisé pour compléter une image existante (elle-même générée), imaginer le hors champ, etc. Ce fut par exemple le cas pour créer les vignettes dans un format différent de la vidéo, mais aussi pour des besoins de « zoom » et « dé-zoom » dans certaines images.
Pour l’animation des vidéos, la plupart des groupes ont choisi RunWay et notamment la fonction Image to Video. La principale plus-value consiste à pouvoir choisir spécifiquement la zone à animer. L’outil présente toutefois (à ce stade) des inconvénients qui peuvent être limitants ; nous y reviendrons. Haiper a également été utilisé par un groupe qui lui a trouvé une qualité supérieure des vidéos générées mais des possibilités de retouche moins nombreuses. Enfin, Pika a été utile pour l’animation des lèvres (lip sync) sur certaines vidéos.
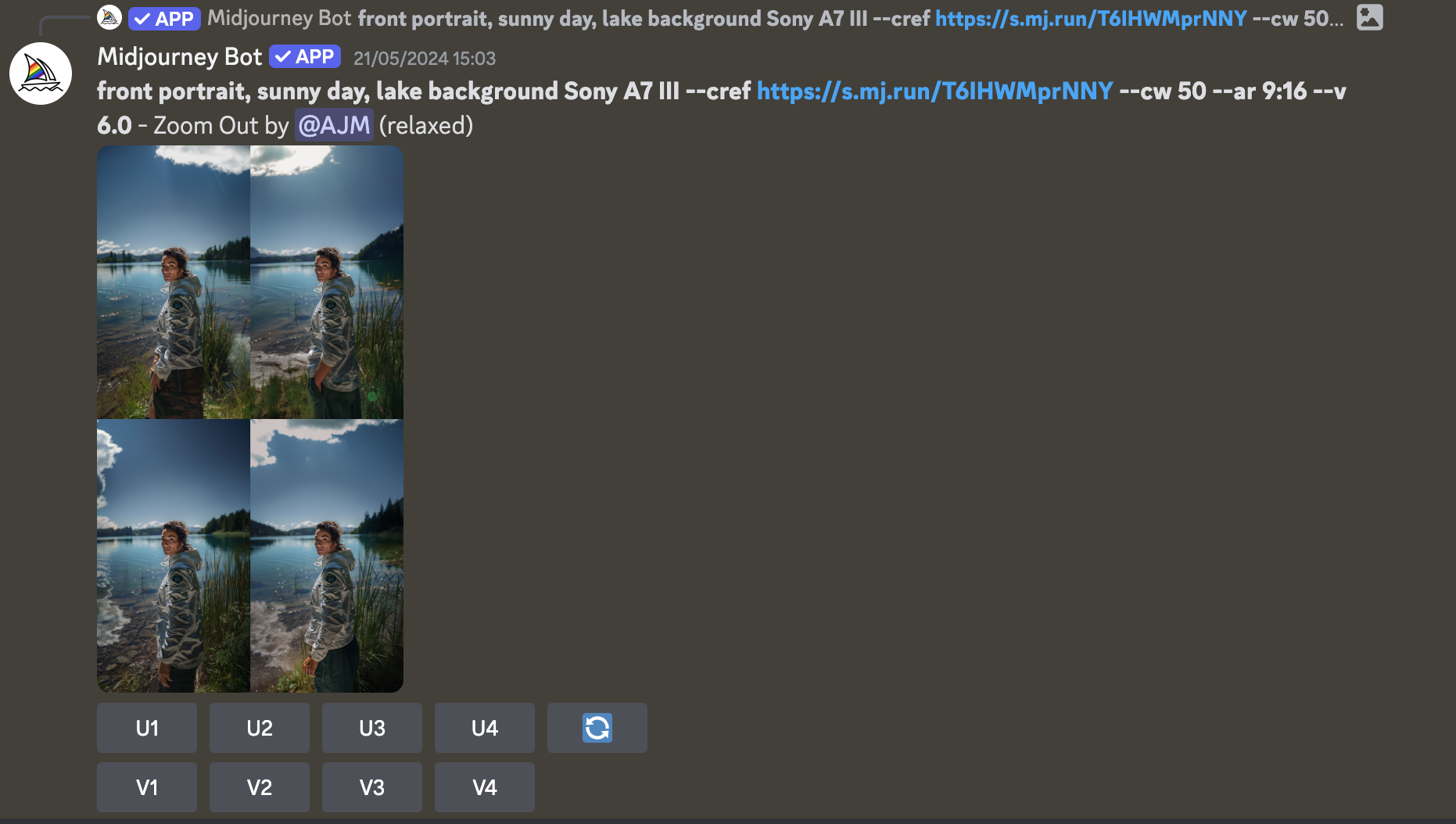
Génération d’un des personnages avec Midjourney.
Côté son, aucune voix n’a été générée artificiellement, afin de garder plus d’authenticité mais également car les résultats en langue française n’étaient pas totalement satisfaisants, en particulier lorsqu’était souhaité un accent local. Un groupe a néanmoins passé sa voix-off dans le logiciel Elevenlabs.io afin de la vieillir, tout en gardant le débit et le timbre d’origine.
Notons enfin l’utilisation du logiciel AfterEffects pour des animations spécifiques qui s’avéraient moins pertinentes avec les outils d’IA (animation d’infographies, d’objets, etc.).
6 enseignements sur la pertinence et les limites des IA génératives pour le journalisme
1. Générer le probable ou l’improbable, le vraisemblable ou l’erreur ?
Au premier abord, les étudiants ont été « bluffés » par les images générées à partir d’un simple prompt et l’apparente rapidité de l’opération (impression par la suite nuancée, nous y reviendrons). Un étudiant résume ce sentiment :
« Nous avons pour la plupart été très impressionnés de la qualité des images et surtout des animations qu’il était possible de générer en quelques minutes avec ces logiciels. De plus, ils sont généralement très simples à prendre en main et très intuitifs à l’utilisation. Réaliser le même type de contenus en ayant recours à des illustrateurs, photographes ou vidéastes professionnels aurait certainement pris un temps considérablement plus long. »
Générer des illustrations du futur, c’est-à-dire vraisemblables mais non réelles, se prête particulièrement bien à l’usage de ces outils conçus pour produire du probable à défaut du vrai. Les étudiants ont toutefois dû être précis dans leur demande pour coller à leur scénario issu de recherches pointues et ne pas laisser trop de marge d’interprétation à l’IA. Les prompts ont permis d’associer dans une même image plusieurs « ingrédients » du futur esquissé : « Il y a plein de détails dans nos images qui reposent sur des infos vérifiées », confirme un étudiant. Par tâtonnements et itérations successives, les groupes ont affiné leurs requêtes jusqu’à obtenir les images souhaitées. Avec des micro-détails, comme par exemple le clignement des yeux dans l’animation des visages, qu’il faut spécifiquement demander.
Car le diable se cache dans les détails… Yeux, mains, cheveux et perspective : les limites actuelles des outils d’IA ont été bien documentées. Nos étudiants les ont expérimentées, y voyant même des similitudes avec l’apprentissage du dessin par l’humain : « C’est un peu comme un jeune artiste qui apprend à dessiner et qui a des difficultés avec certains aspects du dessin (la perspective, les positions particulières, gérer les mains, etc.) ». D’autres limites, comme la difficulté à générer des éléments avec du texte (par exemple, un panneau de signalisation) ont pu être contournées en utilisant des outils plus traditionnels comme Photoshop.
Générer des images a conduit certains, paradoxalement, à interroger leur rapport aux mots. Une étudiante confie : « L’exercice du prompt m’a inspirée sur combien le langage est fascinant : lorsque nous utilisons certains mots en pensant décrire une certaine réalité et que la machine donne un résultat qui n’est pas du tout conforme à nos attentes, nous nous rendons compte que le langage et le vocabulaire peuvent recouvrir des réalités qui sont différentes pour chacun. Et donc de l’importance de s’exprimer de façon précise, particulièrement en tant que journaliste. » Et pourtant, le fait d’être précis ne s’avère pas toujours être un critère suffisant. La marge d’erreur et surtout d’interprétation reste forte : « Au-delà des ordres qu’on donne à l’IA, et qu’on peine parfois à faire respecter, il y a tout le reste : les détails qui sont le fruit de sa propre proposition, et dont il faut arbitrer la plausibilité. » De manière plus prosaïque, des groupes ont changé de langue pour certains prompts : par exemple, « Midjourney interprétait le mot « sauterelle » par « poule » en français. Nous avons donc choisi l’anglais. »
2. Répliquer ou produire de la continuité et de la cohérence
L’un des principaux défis a consisté à assurer la cohérence dans les générations d’images successives, en particulier pour les personnages qui sont au cœur du concept. Pour ce faire, deux fonctionnalités ont été mobilisées : « continuité de personnage » (ou « character consistency ») afin de générer une image fondée sur le visage de la précédente (avec le raccourci « — cref + lien image de référence »). La deuxième commande ajoutée à chaque prompt a permis d’assurer une homogénéité dans le style d’images entre les différentes vidéos (« captured by Sony A7 III »).
Malgré ces commandes, assurer cohérence et continuité s’est avéré délicat face à un programme conçu pour générer à chaque fois un résultat différent. Les personnages, même avec la commande idoine, n’ont pas tout à fait les mêmes traits. Il est encore plus difficile de les faire apparaître dans un même décor, avec les mêmes habits, etc. Face à ces difficultés, les étudiants ont dû faire preuve d’inventivité, par exemple en espaçant à l’image les apparitions de leur personnage ou en les entremêlant de plans de coupe afin d’atténuer la perception des différences. Certains visages se sont révélés plus faciles à dupliquer que d’autres, ce qui a impacté le choix final, comme l’explique une étudiante : « Nous avons vite compris que, si la cohérence d’un personnage était essentielle, dans notre projet, réussir à obtenir une ressemblance serait plus compliqué que prévu. Nous avons dû changer plusieurs fois d’avatar, pour en trouver un qui était reconnaissable d’une scène à l’autre. »
3. De l’image à la vidéo, l’animation par l’IA
Si générer des personnages et scènes cohérentes n’a pas été simple, l’animation de ces images pour les intégrer dans une vidéo a également été source de difficultés. Les animations les plus simples à opérer reposent sur des mouvements sommaires, comme le déplacement d’un nuage, le bruissement des feuilles, etc. Ces légers mouvements ont été dans l’ensemble rapides à créer avec des résultats plutôt satisfaisants. La fonctionnalité permettant d’animer une zone précise d’une image, associée à un prompt clair (un objet spécifique, les lèvres du personnage, etc.) ont été particulièrement utiles.
D’autres animations ont été plus ardues à obtenir. Ainsi, la demande d’un effet de déplacement de la prise de vue pouvait entraîner des déformations à l’intérieur de l’image. L’animation des objets a aussi parfois donné lieu à des surprises : par exemple, au lieu de se mettre à tourner, une éolienne s’envole dans le ciel. Ces déformations sont d’autant plus marquées au-delà des 4 secondes d’animation proposées par défaut par Runway. Les groupes ont fait preuve d’ingéniosité pour contourner ce problème : certains ont créé davantage d’images tandis que d’autres ont choisi de ralentir légèrement leurs vidéos, une technique qui a toutefois un impact sur le rythme d’ensemble.
4. L’animation des personnages et du mouvement : les limites actuelles
L’animation des personnes était le plus délicat, comme en témoigne une étudiante : « J’ai demandé à Runway de faire marcher une femme en avant en tournant le dos à la “caméra”. Le logiciel, sans que je lui demande quoi que ce soit, lui a créé trois coiffures différentes en quatre secondes de vidéo : un chignon, puis une tresse et finalement, une queue de cheval. Dans ce cas-là, même en reformulant ma demande à Runway, le logiciel continuait à changer la coupe de cheveux du personnage. » Un autre se retrouve avec des cheveux bleus, à la faveur d’un mouvement de tête. D’autres sont même victimes d’un véritable morphing, qui transforme radicalement les traits de leur visage mais aussi leurs mains, qui deviennent parfois « des tentacules, des nageoires ou des palmes ».
Une limite a renforcé cet effet : la quasi impossibilité de générer et d’animer des personnes en mouvement. « L’intelligence artificielle n’était pas ou très peu capable de faire marcher les personnes figurant sur les images. En plus de cela, les déplacements et les gestes des acteurs étaient réalisés au ralenti, ce qui rendait l’animation beaucoup moins réaliste », confie une étudiante. Tandis qu’une autre confirme qu’« on n’a jamais réussi à faire marcher ou courir notre personnage, malgré des prompts qui indiquaient “il est pressé”, “il fuit”, “il court”. Il semblait impossible d’avoir une image du personnage dans un mouvement. » Et plus encore de l’animer : soit le mouvement reste très lent et peu naturel, donnant une impression de vidéo au ralenti ; soit des invraisemblances apparaissent de manière marquée. Plusieurs groupes ont été confrontés à cet obstacle et ont dû renoncer à des éléments de leur script (notamment à certains effets de mouvement), tandis que d’autres ont choisi de générer de nouvelles images plus « basiques » et donc plus faciles à animer ensuite.
5. Les IA, machines à générer des déchets ?
Au fil du cours, les étudiants se sont aperçus qu’il était quasiment impossible de produire le « prompt parfait » et que la recherche du résultat escompté nécessitait une approche par « essai / erreur », source de générations et par conséquent de déchets. Un étudiant explique : « Au début, je ne générais pas trop, mais finalement, je me suis rendu compte qu’il fallait générer beaucoup pour trouver la pépite. Je tire au canon sur une mouche pour la tuer. Ça incite à surproduire, avec l’idée qu’on tombera par chance sur la bonne image. » La préoccupation liée à l’impact énergétique d’une telle méthode pose forcément question : « Si cette méthode m’a permis d’obtenir les résultats recherchés plus efficacement, elle m’a interpellé quant à la consommation énergétique nécessaire pour générer autant d’images. » Une autre prolonge : « Si le recours journalistique à l’intelligence artificielle est voué à s’étendre, il serait bon d’avoir les ordres de grandeur de son impact énergétique en tête ». Pour 7 vidéos de 2 minutes environ chacune, ce sont près de 10’000 images qui ont été générées sur MidJourney et 900 prompts d’animation sur Runway, qui pouvaient prendre parfois jusqu’à 10 minutes pour un simple essai.
Ces outils de génération d’images s’avèrent donc, à l’usage, gourmands en énergie mais également en temps d’utilisation et d’attente, contredisant l’idée commune d’un gain de temps important. Un étudiant a calculé, pour la création de la vidéo de son groupe, le temps d’attente total qui s’élève à 45 heures, un minimum au regard du nombre d’images générées pour cette vidéo spécifiquement. Une étudiante s’interroge sur ce rapport au temps :
« Nous sommes habitués à ce que nos clics reçoivent une réponse immédiate. Or, lors des générations d’images et de vidéos, le temps de réponse était parfois de l’ordre de la minute. Des actions que l’on a répétées des milliers de fois. C’est vertigineux. »
6. La chasse aux biais
Dernière embûche dans l’usage d’IA génératives pour ce projet : l’identification et l’éventuelle limitation des biais propres à l’outil. On le sait : les IA, comme d’autres technologies, ne sont pas neutres mais reflètent les valeurs et représentations de leurs concepteurs. Dans le cas des IA génératives, elles sont également « orientées » par la masse des données qui constituent leur base de calcul. La première surprise (et parfois le premier malaise) pour les étudiants a été d’observer la génération de visages extrêmement stéréotypés et lisses. Une étudiante explique : « Nos premières Lucie avaient toujours des airs de top modèles. Il a fallu rajouter artificiellement des détails dans nos prompts pour lui donner une apparence plus réaliste, et encore : notre Lucie finale reste dans les canons de beauté traditionnels. »
Au-delà de la couleur de peau ou des traits du visage, ce sont aussi les postures qui se révèlent très esthétiques et peu naturelles. Et toutes les demandes pour générer des personnes qui sortent d’une norme stéréotypée se sont avérées complexes, voire vouées à l’échec : difficile par exemple d’obtenir une personne âgée qui ne soit pas simplement une personne jeune avec quelques atours de la vieillesse en plus : « On a demandé à Midjourney de créer des images d’une femme de 65 ans. Résultat : cette femme avait l’air d’avoir 37 ans, avec des cheveux gris. » Un étudiant confirme en expliquant les conséquences de ces limites sur leur travail :
« Sans instructions contraires, l’IA va avoir tendance à générer des personnes blanches, jeunes et qui correspondent à des standards de beauté assez précis (corpulence mince, etc.). Nous avions au départ l’idée de faire de Léa une personne de descendance asiatique, mais cette idée a finalement été laissée de côté au fil de notre travail, en partie parce que cela ajoutait des éléments à nos instructions (prompt) et compliquait nos travaux de recherche. »
Ces difficultés ont été encore amplifiées lorsqu’il s’est agi d’animer des personnages qui sortaient quelque peu de « la norme ». Les erreurs et hallucinations décrites plus haut n’en étaient que plus marquées. Les étudiants ont donc souvent dû adapter leurs choix pour favoriser la cohérence, au détriment de leur souhait initial qui devait permettre d’apporter plus de diversité dans les personnages imaginés.
Ils ont également dû composer avec des résultats parfois déroutants comme la sexualisation de certaines postures : par exemple, la demande d’une personne de dos conduit le plus souvent à des représentations dos nu, tandis que la demande pour une posture accroupie aboutissait le plus souvent à une position suggestive. À l’inverse, un autre groupe a eu toutes les peines à générer une image de personne qui nage, les filtres anti-nudité bloquant ce type de requête.
Ces six enseignements ne couvrent de loin pas toutes les réflexions ayant ponctué cette expérience qui a fait émerger de nombreux autres questionnements. Un projet qui a également fait naître quelques ambitions chez nos étudiants qui pressentent que s’ouvre une ère nouvelle où le journaliste devra composer avec ces outils, apprendre à en tirer le meilleur parti et surtout ne pas se laisser submerger par la technique mais en faire un atout, une force. Il y a treize ans, Eric Scherer questionnait : « A-t-on encore besoin des journalistes? » en proposant un « manifeste pour un « journalisme augmenté » ». Ce propos semble plus actuel que jamais.
Un merci tout particulier à Charles-Henry Groult, chef du service vidéo du Monde et chargé d’enseignement à l’AJM, co-responsable du cours Newslab ainsi qu’à Julien Perrot, assistant-doctorant à l’AJM et sur le cours Newslab.
Mais aussi aux étudiants qui ont participé à ce projet (et qui sont pour certains cités anonymement dans cet article) : Charlotte Büser, Yannick Cattin, Julie Collet, Amélie Fasel, Barnabé Fournier, Jean Friedrich, Flavia Gillioz, Tristan Giordano, Simon Gumy, Joanne Habegger, Salomé Laurent, Pablo Laville, Margaux Lehmann, Thibaud Mabut, Solène Monney, Giacomo Notari, Olivia Schmidely, Mathilde Schott, Thomas Strübin et Julia Zeder.
Ainsi qu’à Lena Würlger, journaliste chez ESH Médias qui a accompagné ce projet pour le média partenaire, et Xavier Filliez, rédacteur en chef adjoint du Nouvelliste, qui a participé au pitch final.
Les 7 vidéos sont à retrouver sur les comptes Instagram d’Arcinfo, Nouvelliste, La Côte et sur celui de l’AJM ainsi que sur le site d’Arcinfo.
Davantage de contenus sur l’intelligence artificielle sont à retrouver dans notre dossier thématique.
Cet article est publié sous licence Creative Commons (CC BY-ND 4.0). Il peut être republié à condition que l’emplacement original (fr.ejo.ch) et les auteurs soient clairement mentionnés, mais le contenu ne peut pas être modifié.

Tags: Artificial Intelligence, Digital innovation, innovation, Innovation in Journalism, intelligence artificielle




















[…] текст було вперше опубліковано на французькому сайті EJO 10 липня 2024 року. Українською переклала Олександра […]